
En medio del auge de la Inteligencia Artificial, con numerosos servicios y plataformas funcionando online, muchos usuarios se preguntan si efectivamente es posible ejecutar modelos de IA locales, sin acceso a Internet. Repasamos los detalles respecto de las opciones de Inteligencia Artificial con las que contamos actualmente.
Lo interesante de esto es que podamos disfrutar de modelos de IA locales aún cuando no estemos conectados. Aunque normalmente lo estamos, de vez en cuando puede que nos interese conocer cuáles son los alcances reales de la IA cuando no tiene la posibilidad de recurrir a la casi infinita cantidad de datos e información que hay en línea.
¿Cómo ejecutar modelos de IA locales en Windows, con Ollama?
La primera buena noticia es que puedes ejecutar modelos de IA localmente en Windows gracias a Ollama. Eventualmente hay otros sistemas que se ejecutan de una forma semejante, pero veremos este ejemplo.
- Navega a la web oficial de Ollama y haz click en el botón Descargar
- Selecciona el sistema operativo de tu equipo y confirma la operación de descarga
- Haz doble click en el archivo descargado, luego en Instalar, y sigues las instrucciones
- Ya instalado, verás una ventana emergente que dice que Ollama se está ejecutando
- Inicia tu Terminal. En Windows, pulsa Win + R, escribe
cmdy luego presiona Enter - Descarga el primer modelo de IA con el comando
Ollama pull model(tienes que reemplazar la palabra «model» por el nombre real de Ollama para alguno de sus modelos de lenguaje, como gemma o mistral. Esto puede tardar un rato, así que es mejor que tengas paciencia en esta parte del procedimiento que enseñamos)
¿Cómo comunicarse con modelos de IA sin Internet?
Una vez que hayas ejecutado el primero de los modelos de IA de Ollama, tendrás que aprender a comunicarte con él. No hay muchas diferencias con la forma en la que lo hacemos en los distintos servicios y plataformas ya conocidos, como Gemini o ChatGPT. Si tienes dudas o nunca has interaccionado con la Inteligencia Artificial, sólo haz esto:
- Inicia nuevamente tu Terminal. Escribe el comando
Ollama run llama3sustituyendo «llama3» por tu modelo de IA
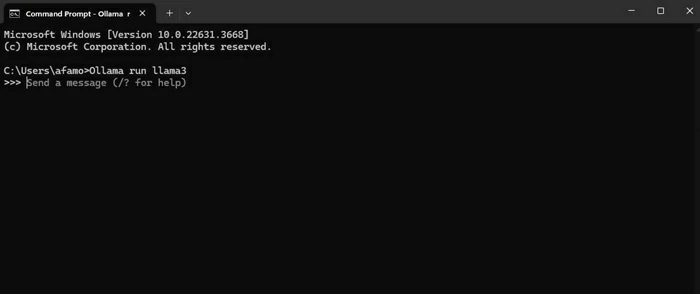
- Finalmente, escribe tu mensaje para la IA y pulsa Enter igual que lo harían en Gemini o en ChatGPT
- La IA te devolverá un mensaje según las indicaciones que le hayas proporcionado
Características de los modelos de IA locales de Ollama
Si no tienes del todo en claro qué modelos de IA locales de Ollama son los que mejor se ajustan a lo que estás buscando, aquí tienes una breve descripción de cada uno de ellos. Igualmente, te recomendamos que hagas unas pruebas con cada uno para identificar con cuál te sientes más cómodo y cuál vale la pena que ejecutes en tu equipo.
- llama3: los modelos ajustados por instrucciones de llama 3 están ajustados y optimizados para casos de uso de diálogo/chat y -en opinión de la propia Ollama- superan a muchos de los modelos de chat de código abierto disponibles en puntos de referencia comunes
- phi3: el modelo está destinado a uso comercial y de investigación en inglés. El modelo proporciona usos para aplicaciones que requieren entornos con restricciones de memoria/cómputo, escenarios vinculados a latencia, razonamiento sólido (especialmente matemático y lógico), y contexto extenso
- mistral: un modelo de parámetros 7B, distribuido con licencia Apache. Está disponible tanto en instrucción (siguiendo instrucciones) como en finalización de texto
- gemma: los modelos se entrenan en un conjunto de datos diverso de documentos web para exponerlos a una amplia gama de estilos, temas y vocabularios lingüísticos. Esto incluye código para aprender sintaxis y patrones de lenguajes de programación, así como texto matemático para comprender el razonamiento lógico.
En cualquier caso, lo cierto es que la IA sin Internet ha llegado para quedarse. Aunque la popularidad de los modelos que se ejecutan en línea es indudable, hay alternativas por las que puedes optar cuando no estés conectado a la red.
¿Tienes alguna pregunta o problema relacionado con el tema del artículo? Queremos ayudarte.
Deja un comentario con tu problema o pregunta. Leemos y respondemos todos los comentarios, aunque a veces podamos tardar un poco debido al volumen que recibimos. Además, si tu consulta inspira la escritura de un artículo, te notificaremos por email cuando lo publiquemos.
*Moderamos los comentarios para evitar spam.
¡Gracias por enriquecer nuestra comunidad con tu participación!