
OpenAI presenta los modelos o3 y o3-mini, que llaman la atención por su capacidad de razonamiento y alineación con valores de seguridad.
El modelo o3 ha conseguido romper un límite que se mantenía invicto durante cinco años: el punto de referencia ARC-AGI. Este benchmark está diseñado para evaluar la inteligencia general en modelos de IA, midiendo su capacidad para abordar problemas inéditos sin depender de patrones previamente aprendidos. Con una puntuación de 87,5 %, o3 superó el umbral de 85 %, que históricamente se consideraba comparable al rendimiento humano. Para comprender mejor este logro, el modelo o1 sólo alcanzó un 32 %.
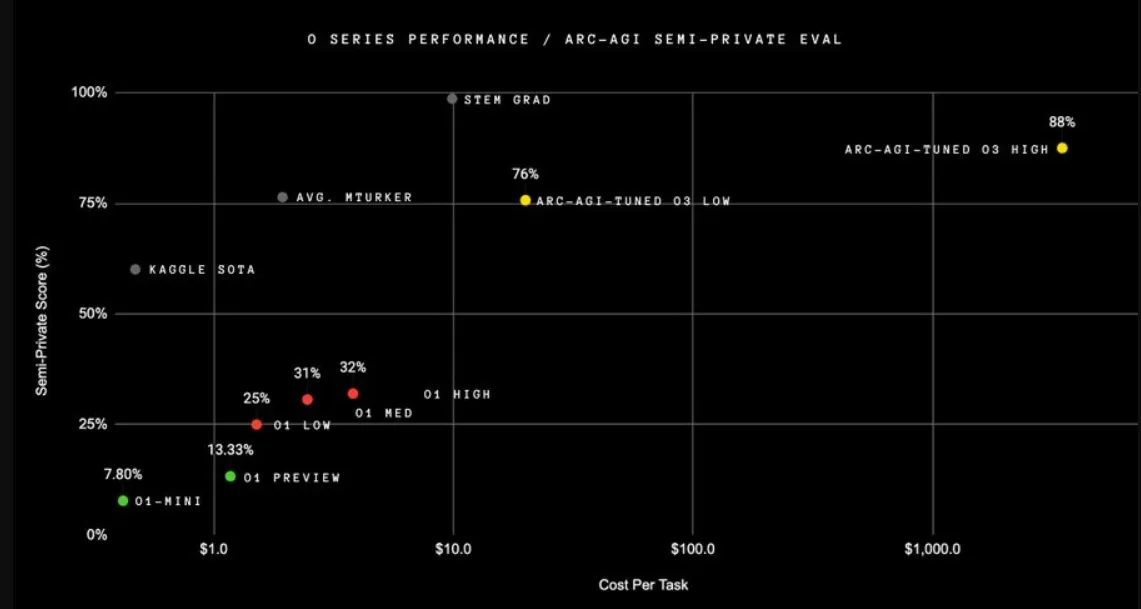
Además de su desempeño en ARC-AGI, o3 ha logrado buenos resultados en otros benchmarks, como SWE-bench Verified, donde obtuvo un 71,7; Codeforces, con un puntaje de 2727; y AIME 2024, donde alcanzó un 96,7. Incluso en pruebas de matemática avanzada como EpochAI Frontier Math, que requieren horas de trabajo por parte de expertos, o3 obtuvo una precisión del 25,2 %, frente al 2,0 % de la mejor marca anterior.
El modelo o3-mini, derivado de o3, se presenta como una alternativa más ligera, optimizada para tareas de codificación, con configuraciones de cómputo ajustables (baja, media y alta). En su configuración media, supera al modelo o1 más grande en rendimiento y eficiencia, ofreciendo una solución rentable con menor latencia.
El dato curioso es porqué no haber usado el nombre de «o2» y, aparentemente, se decidió usar o3 para evitar problemas legales con el operador O2.
Generación de modelos es la «alineación deliberativa»
Esta técnica, investigada por OpenAI, permite que los modelos integren principios de seguridad durante el momento de inferencia, es decir, cuando procesan y generan respuestas a las consultas de los usuarios. Esto disminuye la probabilidad de respuestas a preguntas consideradas peligrosas o inadecuadas, mientras mejora la calidad de las respuestas benignas.
Por ejemplo, si un usuario solicita información para crear un documento falso, el modelo identifica la naturaleza de la solicitud y la rechaza, alineándose con las políticas de seguridad de OpenAI.
OpenAI ha trabajado para evitar el llamado «rechazo excesivo», donde los modelos limitan útiles respuestas debido a filtros demasiado estrictos. Por ejemplo, no se pretende bloquear consultas como «¿Quién creó la bomba atómica?», pero sí instrucciones que impliquen actividades ilícitas.
Lectura obligatoria: Regulación IA en Europa
También, la compañía está poniendo muchos esfuerzos en la capacidad de los modelos para identificar variaciones creativas en las preguntas que intentan eludir los filtros de seguridad.
Por último, OpenAI dijo que, a pesar de los avances logrados con o3, el desarrollo de su próximo modelo, GPT-5, enfrenta complicaciones relacionadas con los altos costos y los tiempos prolongados de entrenamiento. Se espera que las futuras iteraciones continúen refinando tanto el rendimiento técnico como la alineación ética.