
- Using cutting-edge technology such as zero-knowledge proofs (zkProofs), trustless oracles are implemented to ensure data accuracy and reduce dependency on trusted oracles.
- Metacraft Labs introduces the “DendrETH” solution, addressing oracle dependency through innovative technical approaches.
Lido DAO, in collaboration with Lido Ecosystem Grants Organization, has announced a grant project aimed at strengthening the security and decentralization of the DeFi ecosystem.
The primary goal of these grants is to address the reliance on trusted oracles in the Lido protocol and reduce the associated risks.
This initiative seeks to introduce zero-knowledge (zk)-proof trustless oracles to ensure data accuracy and increase protocol security.
Dependency on Oracles and its problems
Reliance on trusted oracles in DeFi protocols has the power to influence token prices, which could unfairly benefit certain users and undermine the principles of decentralization and trustlessness that are fundamental to blockchain technology.
Additionally, oracles control a significant amount of funds within the protocol, making it essential to ensure their continued participation and avoid potential defections. These factors introduce additional security risks and financial overhead for the DAO.
Lido DAO’s approach is to implement trustless oracles that use zero-knowledge proofs (zkProofs) to ensure data accuracy without relying on an oracle operator or third parties.
This is achieved by anchoring the report and proof in the state of the blockchain, eliminating the need to rely on intermediaries.
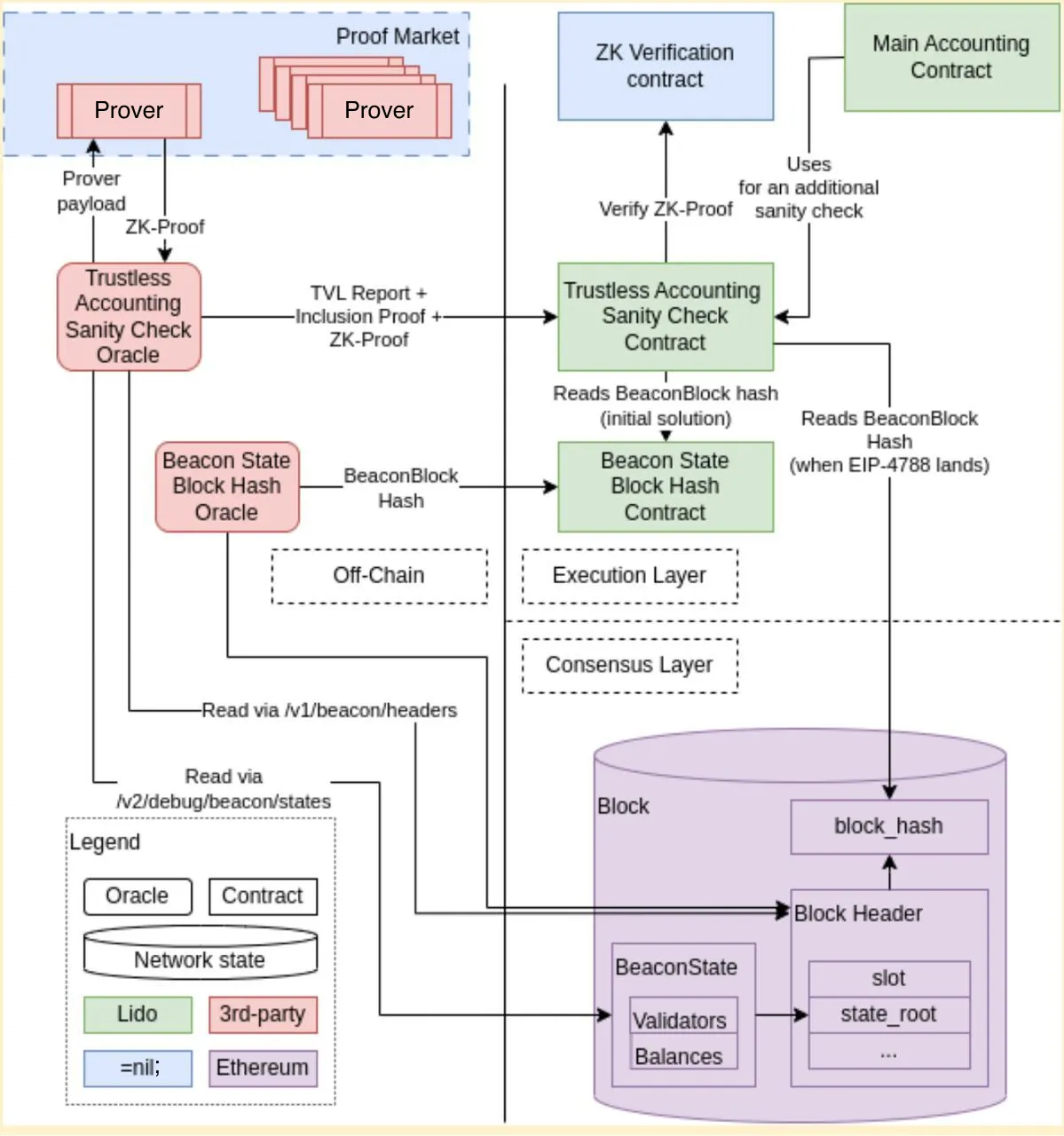
Solution 1 – zkLLVM Oracle
Lido DAO proposes the creation of a dedicated execution layer contract that will report the total value locked of Lido along with active and exited validator counts in a trustless and verifiable manner using zkProofs.
Solution 2 – DendrETH
Metacraft Labs introduces the DendrETH project, which offers two different technical approaches to addressing oracle dependency. One of these approaches uses a fixed set of withdrawal credentials, while the other involves a Merkle accumulator for a set of validators. Both approaches ultimately aim to provide a practical and efficient solution to ensure data accuracy.